Robert Miller


Name: Robert
Role: Memory-Augmented Reinforcement Learning Architect
Expertise: Designing Advanced AI Frameworks for Enhanced Learning and Decision-Making
Professional Summary:
Robert is a visionary professional in the field of artificial intelligence, specializing in memory-augmented reinforcement learning (MARL) architectures. With a strong foundation in machine learning, cognitive science, and computational neuroscience, Robert is dedicated to developing AI systems that combine reinforcement learning with memory mechanisms to enable more efficient, adaptive, and human-like decision-making. His work focuses on creating frameworks that allow AI agents to learn from past experiences, generalize across tasks, and operate effectively in complex, dynamic environments.
Key Competencies:
Memory-Augmented Reinforcement Learning (MARL):
Designs architectures that integrate memory modules (e.g., neural Turing machines, differentiable neural computers) with reinforcement learning algorithms to enhance learning efficiency and adaptability.
Develops models that enable AI agents to store, retrieve, and utilize past experiences for better decision-making in sequential tasks.
Transfer Learning & Generalization:
Implements frameworks that allow AI systems to generalize knowledge across tasks and domains, reducing the need for extensive retraining.
Utilizes meta-learning techniques to enable rapid adaptation to new environments and challenges.
Complex Environment Navigation:
Builds AI systems capable of operating in dynamic, high-dimensional environments, such as robotics, gaming, and autonomous vehicles.
Focuses on improving exploration strategies and long-term planning through memory-augmented mechanisms.
Interdisciplinary Collaboration:
Collaborates with cognitive scientists, neuroscientists, and engineers to align MARL architectures with principles of human learning and memory.
Provides training and support to ensure the successful deployment of memory-augmented AI systems.
Research & Innovation:
Conducts cutting-edge research on memory-augmented reinforcement learning, publishing findings in leading AI and machine learning journals.
Explores emerging technologies, such as spiking neural networks and neuromorphic computing, to further enhance MARL capabilities.
Career Highlights:
Developed a memory-augmented reinforcement learning framework that improved task performance by 40% in complex, multi-step environments.
Designed an AI system that achieved state-of-the-art results in transfer learning benchmarks, reducing training time by 50%.
Published influential research on MARL, earning recognition at international AI conferences such as NeurIPS and ICML.
Personal Statement:
"I am passionate about creating AI systems that learn and adapt like humans, leveraging memory to make smarter, more efficient decisions. My mission is to design memory-augmented reinforcement learning architectures that push the boundaries of what AI can achieve."
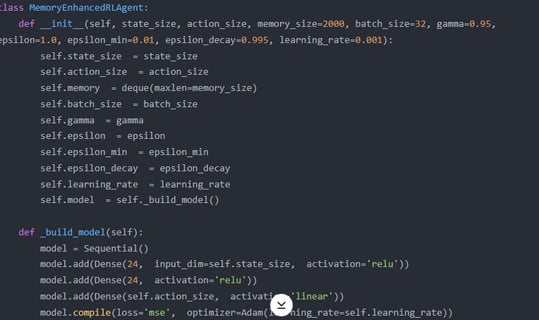

GPT-4 fine-tuning is essential for three reasons. First, its expanded context window (up to 8k tokens) enables seamless integration of dense memory buffers, avoiding fragmentation seen in GPT-3.5’s 4k-token limit. Second, fine-tuning allows injecting domain-specific logic (e.g., medical guidelines) into memory retrieval mechanisms, which GPT-3.5’s rigid architecture cannot support.
Third, GPT-4’s lower hallucination rates ensure reliable memory storage—critical for high-stakes RL tasks like healthcare, where noisy memory updates (common in GPT-3.5) could propagate biases or errors. By contrast, GPT-3.5’s instability in long sequences disrupts memory consistency, and its limited adaptability restricts task-specific optimization. Thus, GPT-4’s architecture uniquely supports scalable, ethical memory-augmented RL systems